Do you have a large collection of physical or digital media you wish was smaller and more portable in size, while still keeping viewing quality? Try Handbrake!
HandBrake is a tool for converting video from nearly any format to a selection of modern, widely supported codecs.
Reasons you’ll love HandBrake:
- Convert video from nearly any format
- Free and Open Source
- Multi-Platform (Windows, Mac and Linux)
Official Site:
https://handbrake.fr/
Handbrake is a way to convert/re-encode the dvd/bluray files/structure from a physical disc or a file to another smaller file - at the cost of some time, and quality (usually not noticeable)
Note: Handbrake does not decrypt encrypted dvd/bluray discs
Some video encoding background:
What is video encoding?
Video encoding is the process of converting digital video files from one format to another. Encoding is also known as “transcoding” or “video conversion.” At the time of recording, the device gives the video file a particular format and other specifications. If the video owner wants to publish the video, s/he must consider the various devices on which the video might play. All of the videos we watch on our computers, tablets, and mobile phones have gone through an encoding process that converts the original source video so that it is viewable on various output formats. This is because many device and browser types only support specific video formats. Often, the goal of the video publisher is to ensure compatibility with a variety of common formats.
Source:
help.ecoding.com
The basics of compression and quality is, pick 2 (maybe just 1)
- Encodes fast
- The faster the encode, usually the less quality and larger file size
- High quality
- The higher the quality, usually the longer the encode and the large the file size
- Smallest file size possible
- The smaller the file, usually the longer the encode and less quality (relatively)
File sizes:
dvds are about 3gb to 5gb
blurays are about 15gb to 40gb .. depending on the movie, audio, etc
Encoding can usually reduce the files sizes to less than half while maintaining a decent quality.
Note: There is no such thing as a smaller file but the same quality! See above and pick one.
Suggested Handbrake Configuration:
After installing and launching, Handbrake is ready to encode your videos.
But first, let’s configure it for a perhaps more optimal experience, and learn a little more about the software
 Click Preferences
Click Preferences
 General Preferences
General Preferences
- You can leave Check for Updates enabled, if you wish
- Check Always clear completed queue items after an encode completes
- This is like auto removing your todo encodes
- Check Show the encode status in the application title bar, if you wish
- Check Reset to ‘Do nothing’ when the app is re-launched
- You can set actions when your video is done encoding, such as shutdown
- You can also enable sounds on completion
 Output Files Preferences
Output Files Preferences
- Handbrake can auto name your encoded files to simplify some file management.
- To have the output file be the same as the input, change the File Format to {source}
- Also you can set your default destination, which will save you some clicking for each encode.
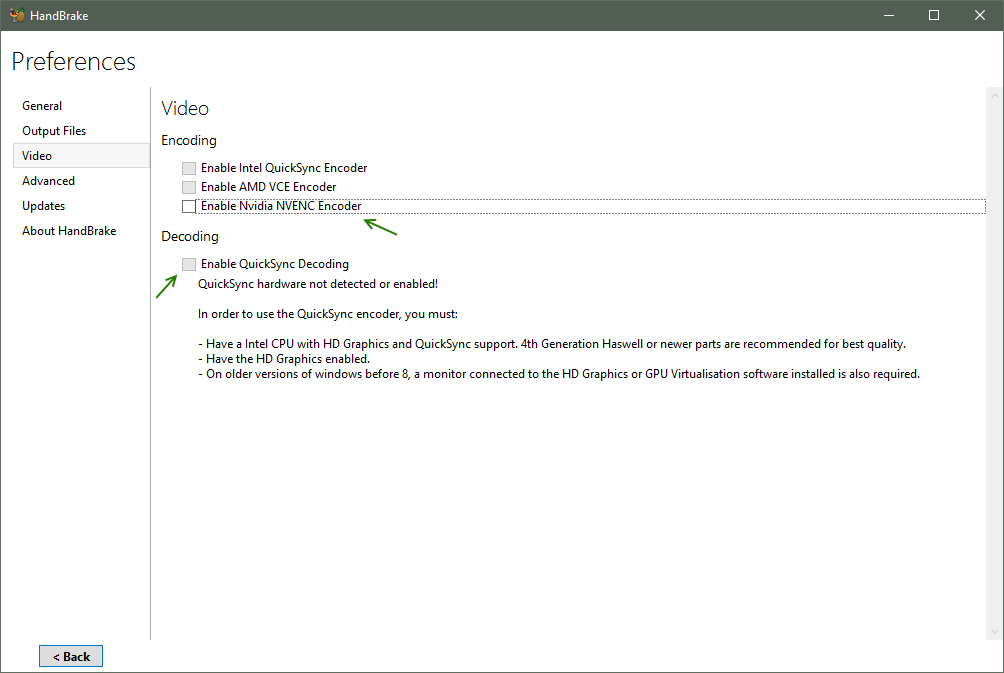 Video Preferences
Video Preferences
- Encoding
- You can encode video files using your video card, if supported
- Generally, video cards will encode files faster than cpus, but the quality will be slightly less and the file size will be slightly larger
- You can also encode video files using your cpu
- Generally, cpus will encode files in higher quality and smaller file sizes
- If you have a 6 core or 8 core cpu, cpu encoding time could be comparable to encoding using a video card
- Recommendation is to uncheck all video card options thus encode files using your cpu, but of course, try both and see which you prefer.
- Decoding
- Decoding options enable hardware support for specific devices, such as a specific cpu or video card; If you play back a encoded video on a unsupported device, the quality and performance may be less.
- Recommendation is to uncheck all decoding options
 Advance Preferences
Advance Preferences
- Raise the Priority Level of the Handbrake process to Above Normal. Video encoding is an intensive process and you should not use your pc for other tasks at the same time; but of course you can, but encoding will take longer.
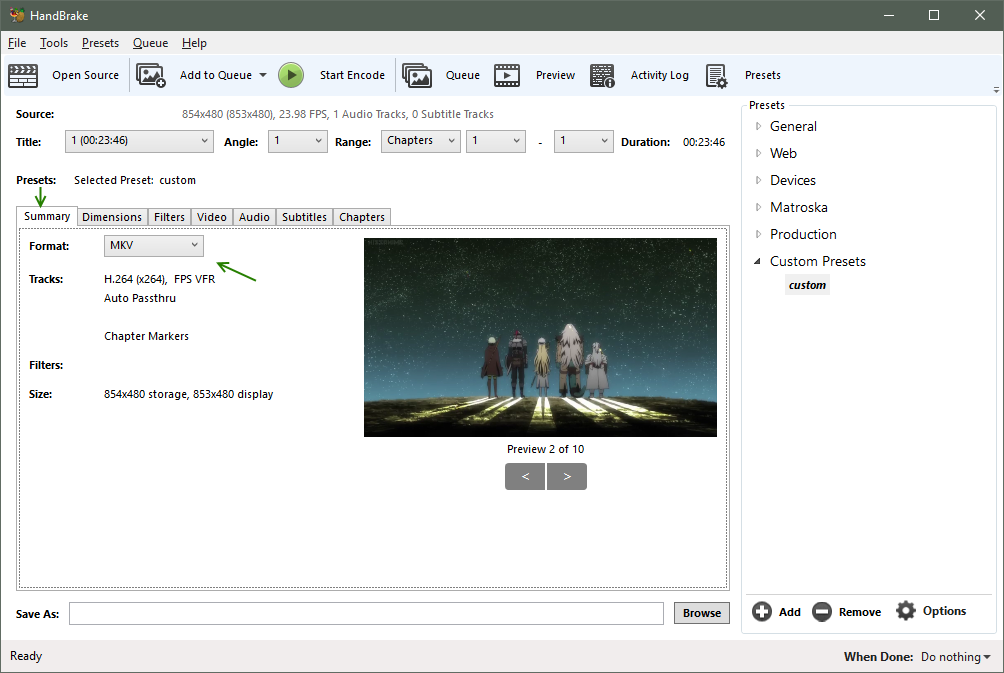 Summary
Summary
- After loading a file or disc, you can the adjust the encoding options
- While all these options can be saved to a preset, I will go through the important ones first
- Format
- Choose the file extension; mkv and mp4 are file containers for the video and audio streams
- mp4 is supported by more devices (often older hardware players), but allows only one subtitle
- mkv allows unlimited audio, subtitles, is easily editable - preferred extension
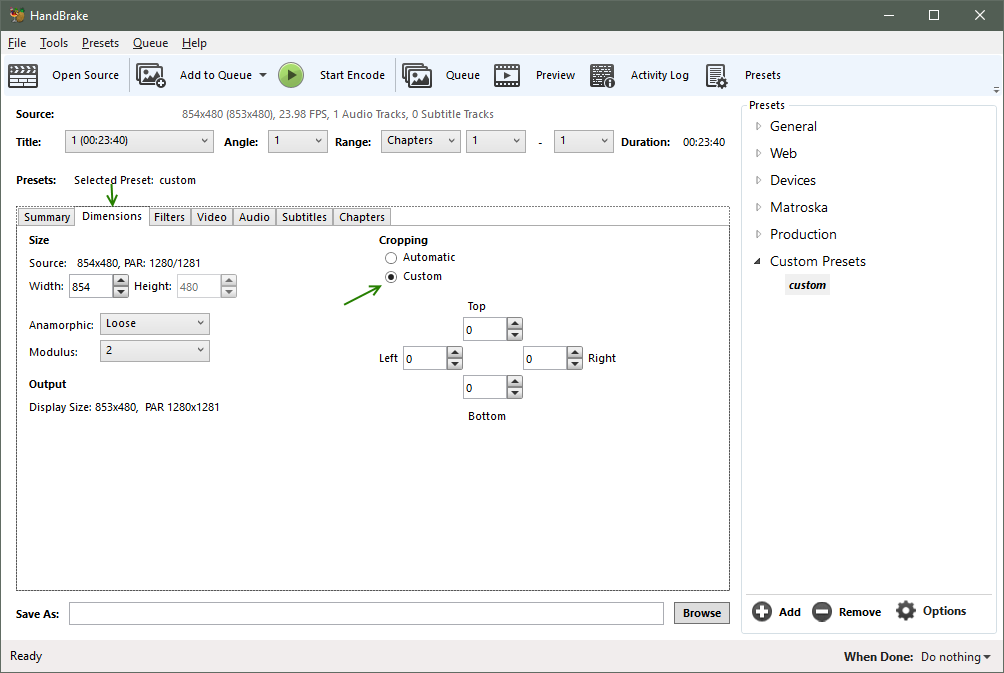 Dimensions
Dimensions
- Width and Height will default to the width and height of your file. You can reduce the width/height if you are trying to achieve a small file size. Keeping the same width/height is preferred for video archive and for optimal quality.
- Cropping - Handbrake can auto crop top/bottom and left/right black bars, so the video will appear to fill more of the screen on playback. Note however, that some movies will play subtitles, or foreign languages, or other information in the black bars. So it is safer to just leave the video size as is. Choose custom and enter 0 for all dimensions.
 Filters
Filters
- Filters allow you to maybe enhance the quality of a poor quality video, such as a video from vhs, or an old camcorder, or a bad internet stream. But often, if your source is a dvd/bluray, you will want to turn off all filters and just take the video as is.
 Video (lots of options here)
Video (lots of options here)
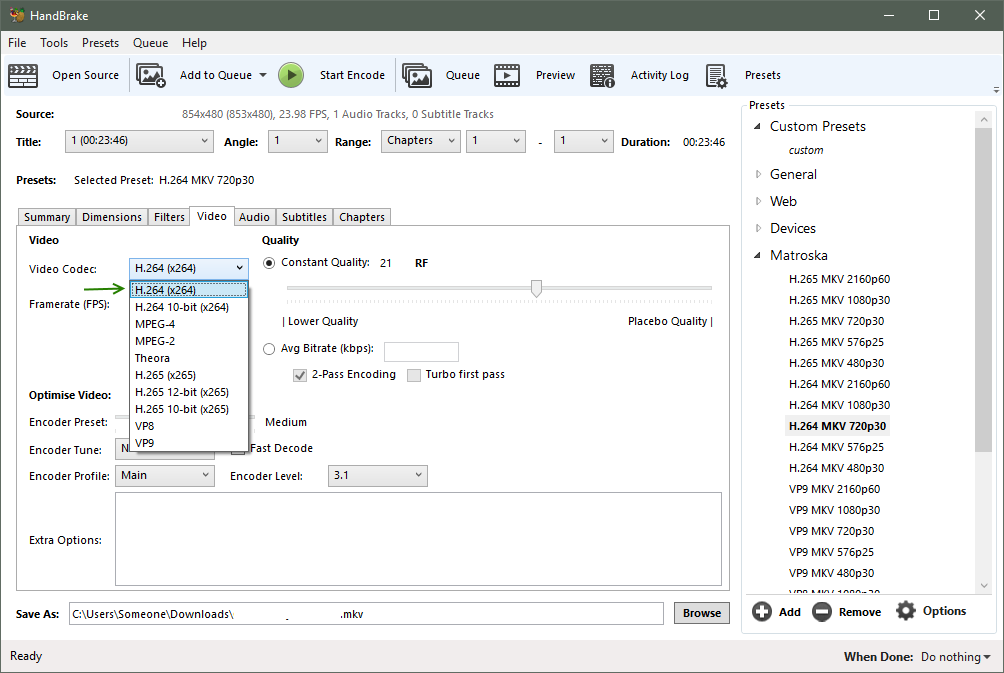 Video Codec
Video Codec
- x264 has been around for a while and is optimized for video archival to produce a good balance of file size and quality. Choose x264
- x265 is relatively newer, and is optimized to stream video at a decent quality for a small bandwidth (file size). At some point, x265 may also be good for video archival.
- The other codecs are older or less popular, but may be required depending on the device you need to playback the videos. Your playback device (pc, tv streamer, phone, etc) needs to support the video codec you are using. While you can try searching the internet for your devices supported codecs, it’s usually easier to just encode a video file and try. x264 has wide support on new and old devices while x265 has wide support on ‘newer’ devices (last few years)
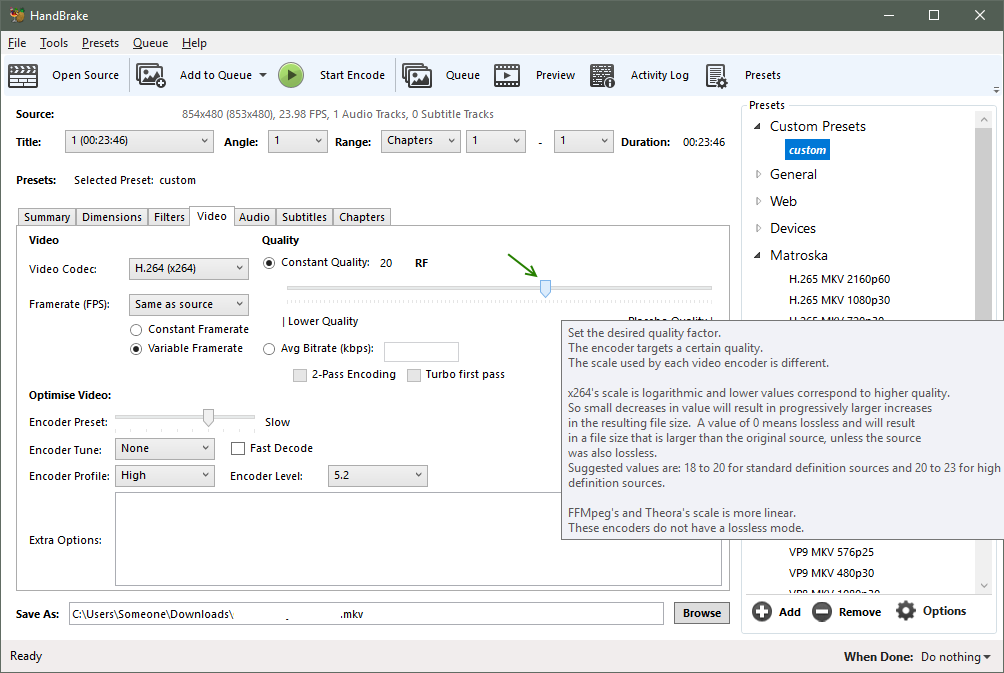 Quality
Quality (everyone wants it!)
- Constant Quality - Handbrake will try to keep a relatively constant quality throughout the video. Simple scenes with little movement or variation will have a lower bitrate, but still look good since little is happening, while fast moving scenes or lots of variation will have a higher bitrate, averaging out to a optimal file size for a given quality.
- Choose a Quality Rate Factor (RF) of 20
- For testing other settings, such as subtitles or audio, choosing a much higher RF such as 40 will result in a blocky video, but it will encode much faster.
- Average Bitrate - uses a fixed bitrate, independent of the scene, resulting in a larger file size for a relative quality. Some older devices may require a fixed bitrate.
Handbrake documentation
https://handbrake.fr/docs/en/latest/workflow/adjust-quality.html
Recommended settings for x264 and x265 encoders:
- RF 18-22 for 480p/576p Standard Definition1
- RF 19-23 for 720p High Definition2
- RF 20-24 for 1080p Full High Definition3
- RF 22-28 for 2160p 4K Ultra High Definition4
Raising quality minus 1-2 RF may produce better results when encoding animated Sources (anime, cartoons). Lower quality settings may be used to produce smaller files. Drastically lower settings may show significant loss of detail.
Using higher than recommended quality settings can lead to extremely large files that may not be compatible with your devices. When in doubt, stick to the recommended range or use the default setting for the Preset you selected.
 Framerate (FPS)
Framerate (FPS)
- The framerate the encoded video will playback on. Unless your playback device has a specific requirement, choose Same as source
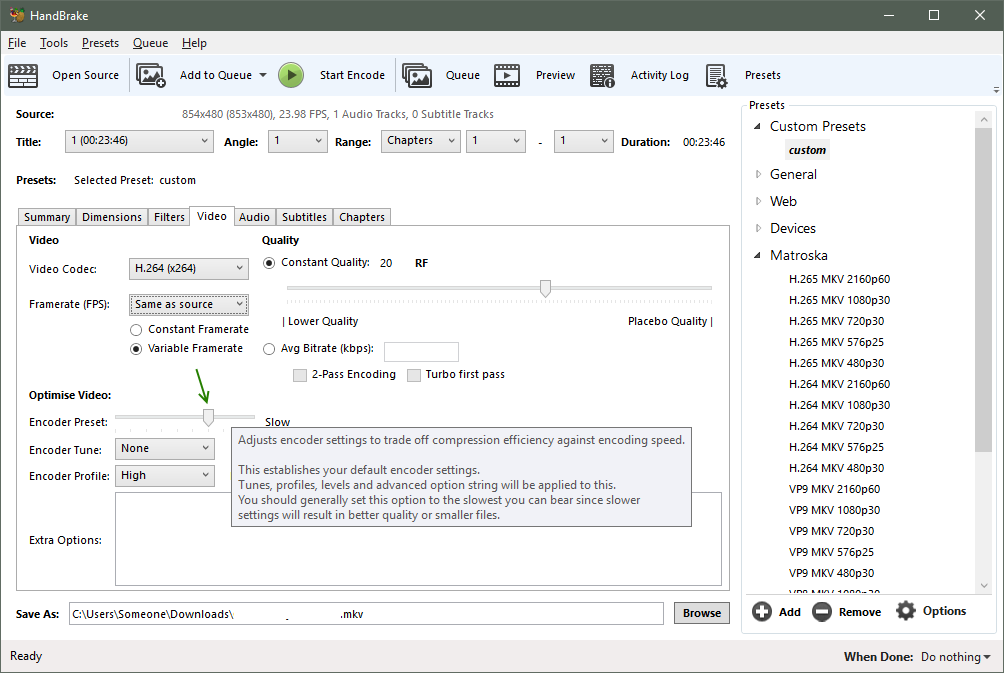 Encoder Preset
Encoder Preset
- Determines how much time Handbrake spends analyzing a scene to optimize quality and size.
- Choose Slow, for a good compromise of time and quality
- Choose Faster if just testing subtitles or audio tracks
Encoder Profile and Level
- Choose the highest values for video archivals; Only choose lower values if your playback device requires it
- Encoder Profile - Choose High
- Encode Level - Choose 5.2 (or highest number)
 Audio
Audio
- You can add or remove multiple audio tracks that your source video file contains.
- Choose Auto Passthru to keep the audio quality
- You can choose other encodings to save space and the cost of quality
 Audio Defaults
Audio Defaults
- You can set defaults for all new video files (Click Selection Behavior)
- Select the languages you want
- Select the audio codes you want
- AC3 is the most common and widely supported
- HD often increases the file size and requires supporting hardware for playback
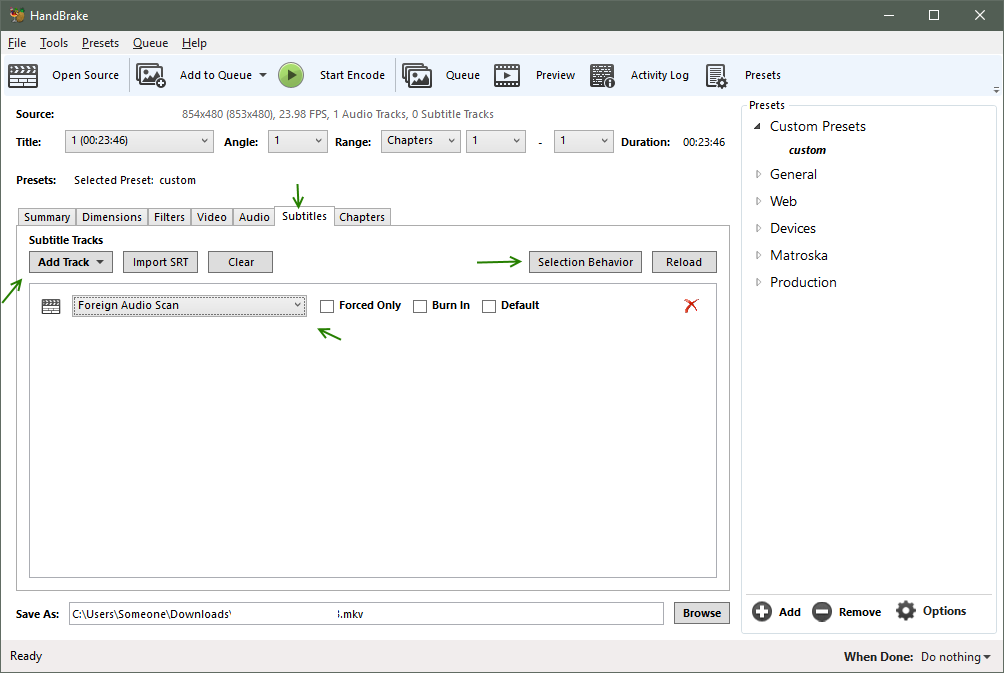 Subtitles
Subtitles (understand what they are saying!)
- You can add or remove multiple subtitles that your source video file contains
- Even if you do not like viewing subtitles yourself, they are still useful if you are trying to figure out what an actor is trying to say! Add all subtitles for you language.
- Some video files or discs will have foreign subtitles as a special track which Handbrake can try to find
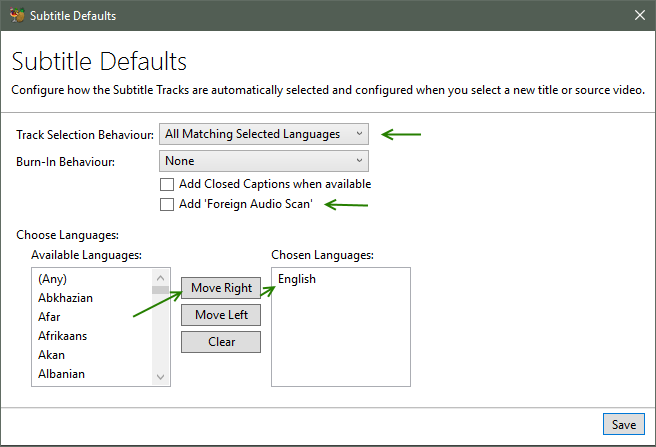
Subtitle Defaults
- You can set defaults for all new video files (Click Selection Behavior)
- Select the languages you want
- Subtitles can be turned on or off by most video players.
- Burning in subtitles means the subtitle is part of the video and always plays.
- If you use mkv, you do not have to burn in subtitles
- If you use mp4, you can have only one subtitle
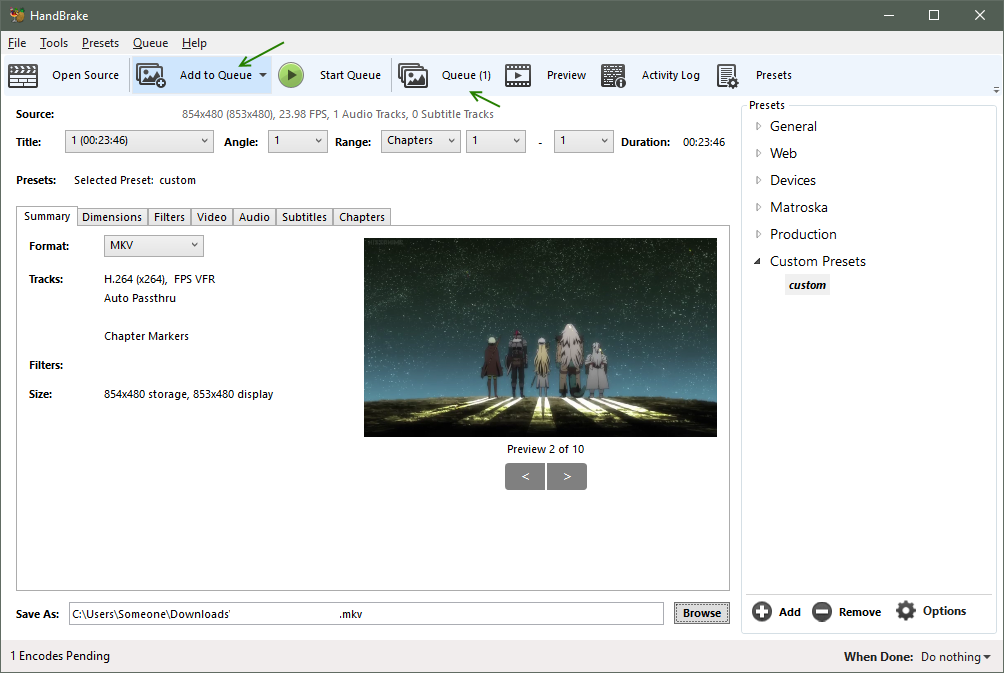 Add to Queue
Add to Queue
- Handbrake has a queue system, which allows you to configure multiple video encodes and then let them encode automatically one after another, such as overnight, or while you do other things.
- Click Add to Queue when you are done configuring your encoding options
 View Queue
View Queue
- When you are ready to process the queue, click Queue
- You can mouse over a queued video to see a summary
- You can choose an action to perform when the queue is finished, such as Suspend
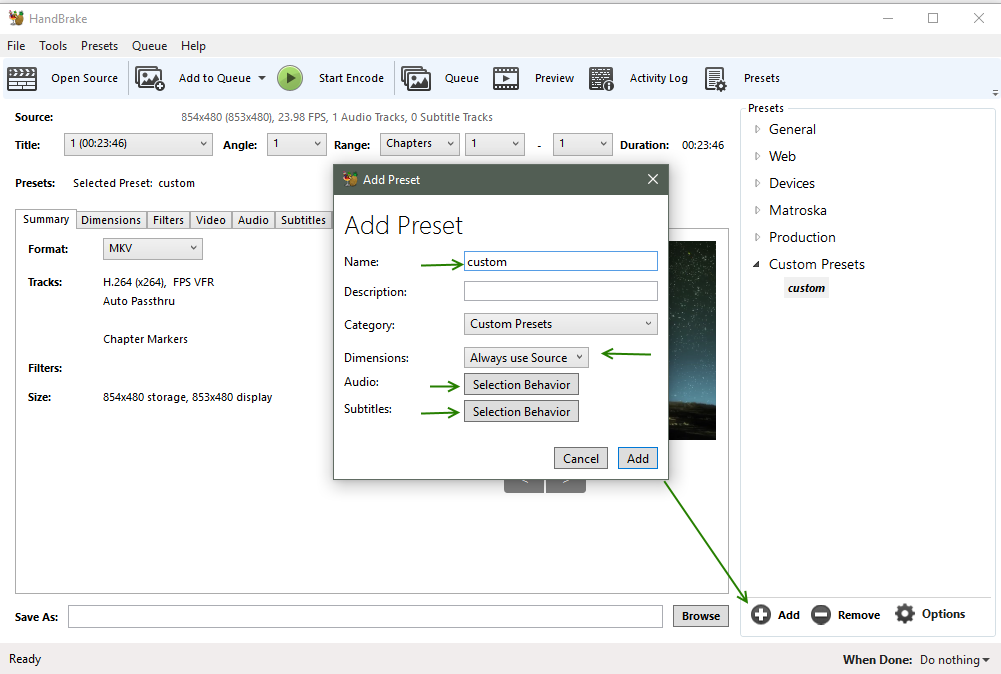 Presets
Presets
- Presets allow you to apply your encoding configuration for the current video to all new videos
- Click Presets to show the preset bar
- Click Add to create a preset, or Options Update Preset to update a selected preset
- Enter a name
- Dimensions - select Always use Source, unless you are targeting a specific size
- Audio and Subtitles will use your defaults if you’ve set them up, else do so now
Note: In the past, Handbrake presets were a little flakey when it came to editing or viewing; it took some trial and error. But with version 1.2.0 and on, presets seem to be more stable.
Note: While you can export presets, choose Options, presets from one version may not work with the next version, so it may be good to take a screenshot of the important options, or write them down.
Sally forth and encode!
Well, that’s a good overview of Handbrake’s configuration and you now have a good start on encoding your video files. But before encoding the world, it would be smart to encode one or two videos with different settings to get a feel of the end results.
Then Sally forth and encode!
For more information, reference the official docs at
https://handbrake.fr/docs/en/latest/
Other related software which may be useful:
- videolan- play any movie (aka vlc)
- kodi- nice graphical interface to play movies
- tinymediamanager- download poster,fanart,movie.nfo for library; video library browser
- emdb- video library browser
- mkvtoolnix- edit mkv file headers ie turn off/on subtitles, change audio labels/order/default, etc
- filebot- rename copied/archived files (good for tv series)
- aren- advanced file renamer
- mediainfo lite - video file info
- avidemux- edit video/audio
- http://thetvdb.com/- movie/tv info/posters
-End of Document-
Thanks for reading